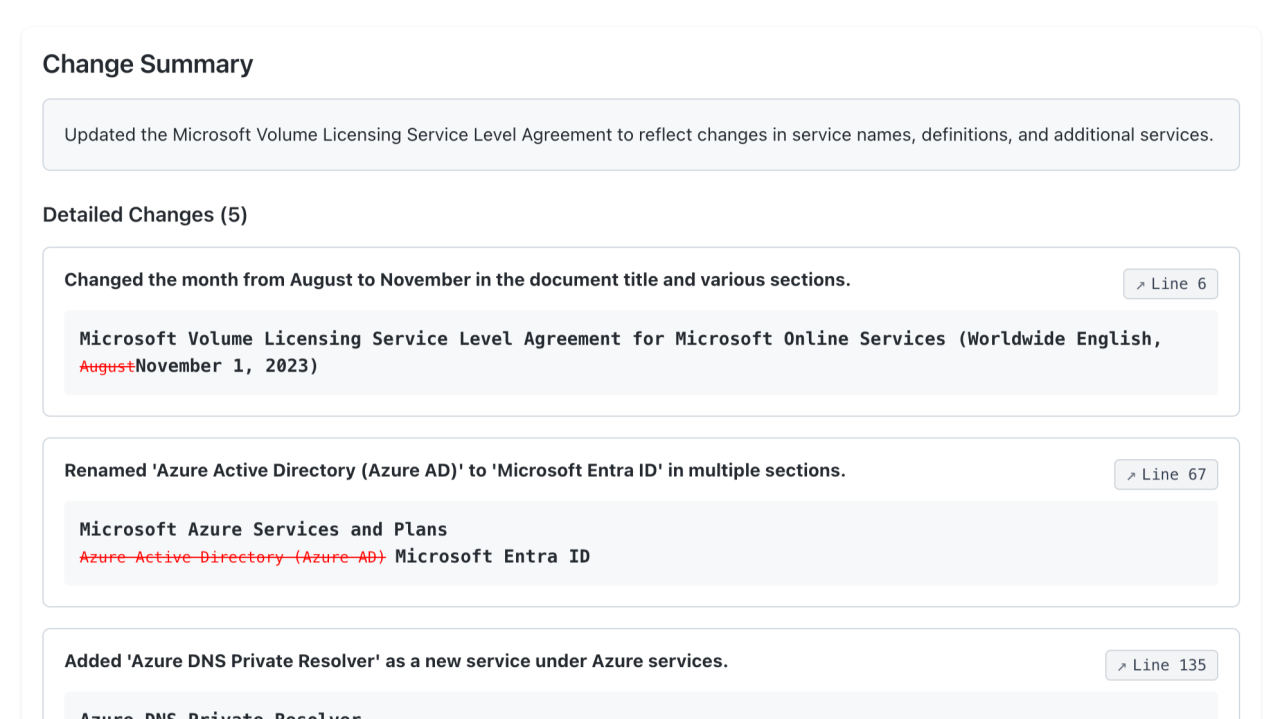
I often see customers eager to leverage generative AI to better understand and reason over their existing data. One common scenario is comparing different revisions of a single long-form document. While developers easily track code changes and even get commit messages suggested by tools like GitHub Copilot, handling similar insights for text documents like Word files can be tricky. Changelogs in documents are best practice, but they’re often missing, incomplete, or hard to follow.
This led me to create a demo solution that uses Azure Document Intelligence and Azure OpenAI to automatically generate a meaningful changelog from two document revisions. The idea is simple:
- Extract text from two DOCX versions (using OCR if needed).
- Compute a diff to identify changes.
- Use Azure OpenAI to summarize those changes into an easy-to-read list, complete with citations and before/after snippets.
This approach allows non-technical users to quickly see what changed without sifting through raw diffs. It’s like having a smart “commit message” for any evolving long-form doc.
How It Works
Step 1: Converting Documents to Text (with OCR)
First, we feed both the old and new DOCX revisions into Azure Document Intelligence. If pages are scanned images, OCR kicks in, returning clean, structured text. This ensures we always get a workable text output, no matter the source format.
from azure.ai.documentintelligence import DocumentIntelligenceClient
from azure.core.credentials import AzureKeyCredential
def convert_to_text(docx_path: str) -> str:
endpoint = settings.AZURE_DOC_INTELLIGENCE_ENDPOINT
key = settings.AZURE_DOC_INTELLIGENCE_KEY
if not endpoint or not key:
raise HTTPException(status_code=500, detail="Azure Document Intelligence credentials not configured")
document_intelligence_client = DocumentIntelligenceClient(endpoint=endpoint, credential=AzureKeyCredential(key))
with open(docx_path, "rb") as f:
file_bytes = f.read()
poller = document_intelligence_client.begin_analyze_document("prebuilt-layout", bytes_source=file_bytes)
result = poller.result()
return result.content
Step 2: Computing the Diff
Once we have text for both versions, we run them through a diff function. This gives us a unified diff-like format and a similarity score. If the documents are too different, we warn the user. Otherwise, we move on to changelog generation.
from diff_match_patch import diff_match_patch
def compute_diff(text1: str, text2: str) -> dict:
dmp = diff_match_patch()
diffs = dmp.diff_main(text1, text2)
dmp.diff_cleanupSemantic(diffs)
# Create a unified diff-like output
diff_text = _create_unified_diff(text1.splitlines(), text2.splitlines(), diffs)
similarity = _calculate_similarity(diffs)
return {"diff_text": diff_text, "similarity_score": similarity}
def _calculate_similarity(diffs) -> float:
unchanged_chars = sum(len(text) for op, text in diffs if op == 0)
total_chars = sum(len(text) for _, text in diffs)
return unchanged_chars / total_chars if total_chars > 0 else 1.0
Step 3: Generating a Human-Friendly Changelog
We then prompt Azure OpenAI to convert the diff into a structured summary. Instead of raw pluses and minuses, we get a list of bullet points explaining what changed, where, and how. It can include search terms and before/after text snippets.
async def generate_changelog(diff_text: str) -> dict:
changelog = await client.chat.completions.create(
model=settings.AZURE_OPENAI_MODEL,
response_model=Changelog,
messages=[
{
"role": "system",
"content": "You are a precise changelog generator..."
},
{
"role": "user",
"content": f"Generate a changelog with searchable citations.\nDiff:\n{diff_text}\n"
}
],
temperature=0.1
)
return changelog.model_dump()
Putting It All Together
The /upload endpoint accepts two document versions, processes them, computes the diff, and then generates the changelog. If documents aren’t closely related, it warns the user. If they are, it returns a user-friendly summary of changes.
@router.post("/upload")
async def upload_documents(
source: UploadFile | None = None,
target: UploadFile | None = None,
source_url: str | None = Form(None),
target_url: str | None = Form(None)
):
# ... (file handling and validation)
source_text = convert_to_text(source_tmp.name)
target_text = convert_to_text(target_tmp.name)
diff_result = compute_diff(source_text, target_text)
if diff_result["similarity_score"] < settings.SIMILARITY_THRESHOLD:
return {"warning": "Documents appear to be unrelated"}
changelog = await generate_changelog(diff_result["diff_text"])
return {
"diff_text": diff_result["diff_text"],
"similarity_score": diff_result["similarity_score"],
"changelog": changelog
}
Why This Matters
Organizations have tools to understand code changes, but other data like documents often remain opaque. Automating both the extraction and summarization steps bridges that gap, allowing anyone — from compliance officers to project managers — to quickly grasp what’s new.
During testing, I’ve found that even a smaller, cost-effective model like GPT-4o-mini can handle these tasks efficiently. This not only reduces expenses but also makes the solution scalable for handling larger documents without breaking the bank.
Interested in Trying It Out?
The code for this solution accelerator is available on GitHub. Feel free to explore, experiment, and adapt it to your needs.
